Interactive online version:
A Life Cycle Model: The Distribution of Assets By Age#
National registry data on income and wealth from Scandinavian countries has recently become available (with a lot of security) to some (lucky!) researchers. These data offer a uniquely powerful tool for testing (and improving) our models of consumption and saving behavior over the life cycle.
But as of this writing (in March of 2019), the data are so new that there do not seem to be any published attempts to compare the data to the implications a standard life cycle model with income uncertainty, constraints, and other modern features.
This notebook is an example of how one could counstruct a life cycle model with the HARK toolkit that would make predictions about the model analogues of the raw data statistics that are available.
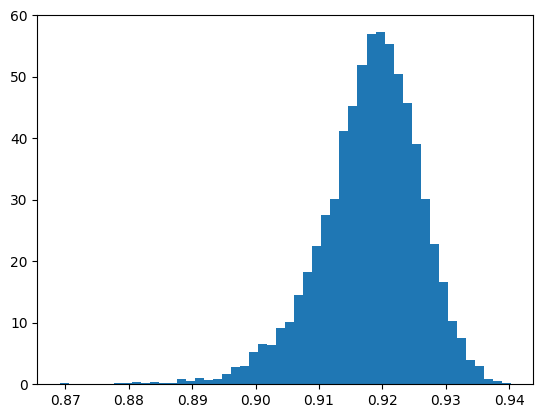
For example, the papers have shown information about the growth rate of assets at different ages over the life cycle. Here, we show how (under a given parameterization) we could produce the life cycle model’s prediction about the distribution of assets at age 65 and age 66, and the growth rate between 65 and 66.
The parameters of the model have not been optimized to match features of the Norwegian data; a first step in “structural” estimation would be to calibrate the inputs to the model (like the profile of income over the life cycle, and the magnitude of income shocks), and then to find the values of parameters like the time preference rate that allow the model to fit the data best.
An interesting question is whether this exercise will suggest that it is necessary to allow for ex ante heterogeneity in such preference parameters.
This seems likely; a paper by Carroll et al (2017) (all of whose results were constructed using the HARK toolkit) finds that, if all other parameters (e.g., rates of return on savings) are the same, models of this kind require substantial heterogeneity in preferences to generate the degree of inequality in U.S. data.
But in one of the many new and interesting findings from the Norwegian data, Fagereng et al (2020) have shown that there is substantial heterogeneity in rates of return, even on wealth held in public markets.
Derin Aksit has shown that the degree of time preference heterogeneity needed to match observed inequality is considerably less when rate-of-return heterogeneity is calibrated to match these data.
[1]:
# Initial imports and notebook setup, click arrow to show
import EstimationParameters as Params # Parameters for the consumer type and the estimation
import numpy as np
import HARK.ConsumptionSaving.ConsIndShockModel as Model # The consumption-saving micro model
from HARK.utilities import plot_funcs # Some tools
[2]:
# Set up default values for CRRA, DiscFac, and simulation variables in the dictionary
Params.init_consumer_objects["CRRA"] = (
2.00 # Default coefficient of relative risk aversion (rho)
)
Params.init_consumer_objects["DiscFac"] = (
0.97 # Default intertemporal discount factor (beta)
)
Params.init_consumer_objects["PermGroFacAgg"] = (
1.0 # Aggregate permanent income growth factor
)
Params.init_consumer_objects["aNrmInitMean"] = -10.0 # Mean of log initial assets
Params.init_consumer_objects["aNrmInitStd"] = (
1.0 # Standard deviation of log initial assets
)
Params.init_consumer_objects["pLvlInitMean"] = (
0.0 # Mean of log initial permanent income
)
Params.init_consumer_objects["pLvlInitStd"] = (
0.0 # Standard deviation of log initial permanent income
)
[3]:
# Make a lifecycle consumer to be used for estimation
LifeCyclePop = Model.IndShockConsumerType(**Params.init_consumer_objects)
[4]:
# Solve and simulate the model (ignore the "warning" message)
LifeCyclePop.solve() # Obtain consumption rules by age
LifeCyclePop.unpack("cFunc") # Expose the consumption rules
# Which variables do we want to track
LifeCyclePop.track_vars = ["aNrm", "pLvl", "mNrm", "cNrm", "TranShk"]
LifeCyclePop.T_sim = 120 # Nobody lives to be older than 145 years (=25+120)
LifeCyclePop.initialize_sim() # Construct the age-25 distribution of income and assets
LifeCyclePop.simulate() # Simulate a population behaving according to this model
[4]:
{'aNrm': array([[0.15125005, 0.15125664, 0.15126049, ..., 0.15124978, 0.15125783,
0.15124518],
[0.36787773, 0.358074 , 0.15719738, ..., 0.24159645, 0.34020441,
0.24159398],
[0.43154017, 0.48740224, 0.25976208, ..., 0.33696813, 0.44766406,
0.24124603],
...,
[0.02445602, 0.3823419 , 0.30096221, ..., 0.3965249 , 0.52642809,
0.65668486],
[0.15126787, 0.39902143, 0.20553988, ..., 0.36277515, 0.47478335,
0.7918587 ],
[0.16042668, 0.35480488, 0.13313599, ..., 0.42423289, 0.60776456,
0.75771854]]),
'pLvl': array([[0.98306182, 0.98306182, 0.94158876, ..., 1.19556632, 0.94158876,
1.05822383],
[0.85692606, 0.92563997, 0.92563997, ..., 1.42937882, 1.04038564,
1.26517677],
[0.74697466, 1.0227634 , 0.94409967, ..., 1.57935741, 0.97961543,
1.29040773],
...,
[0.36046482, 0.96031227, 0.37276982, ..., 0.90918925, 2.76173821,
1.43120532],
[0.98306182, 0.97946343, 0.37276982, ..., 1.08699604, 3.30184119,
1.45974733],
[0.92563997, 0.99899651, 0.37276982, ..., 1.20104988, 2.87818497,
1.27244848]]),
'mNrm': array([[1.00001966, 1.00003455, 1.00004326, ..., 1.00001905, 1.00003724,
1.00000866],
[1.3509863 , 1.33772651, 1.01318639, ..., 1.16790567, 1.31326844,
1.16790171],
[1.43475488, 1.50606028, 1.19634896, ..., 1.30860691, 1.45554145,
1.16721565],
...,
[1.08145693, 1.36577256, 1.43820362, ..., 1.38724882, 1.52116765,
1.68915494],
[1.00005993, 1.38617839, 1.30999108, ..., 1.34167903, 1.45359275,
1.83542774],
[1.02017497, 1.32619545, 1.21170607, ..., 1.42156841, 1.59861097,
1.79037301]]),
'cNrm': array([[0.84876961, 0.84877791, 0.84878277, ..., 0.84876927, 0.84877941,
0.84876348],
[0.98310857, 0.9796525 , 0.85598901, ..., 0.92630922, 0.97306403,
0.92630773],
[1.0032147 , 1.01865804, 0.93658688, ..., 0.97163878, 1.00787739,
0.92596962],
...,
[1.05700091, 0.98343065, 1.13724141, ..., 0.99072391, 0.99473956,
1.03247009],
[0.84879206, 0.98715696, 1.1044512 , ..., 0.97890388, 0.9788094 ,
1.04356905],
[0.85974829, 0.97139056, 1.07857008, ..., 0.99733552, 0.9908464 ,
1.03265447]]),
'TranShk': array([[1. , 1. , 1. , ..., 1. , 1. ,
1. ],
[1.1722675 , 1.1722675 , 0.85470368, ..., 1.0376015 , 1.1722675 ,
1.0376015 ],
[1.00006632, 1.1722675 , 1.0376015 , ..., 1.08339327, 1.08339327,
0.92323938],
...,
[1. , 0.85470368, 1. , ..., 0.92323938, 1.08339327,
0.92323938],
[1. , 1.00006632, 1. , ..., 1.00006632, 1.00006632,
1.1722675 ],
[0.85470368, 0.92323938, 1. , ..., 1.08339327, 1.0376015 ,
0.85470368]])}
[5]:
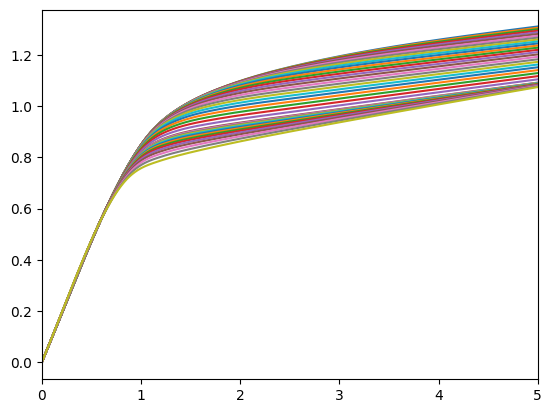
# Plot the consumption functions during working life
print("Consumption as a function of market resources while working:")
mMin = min([LifeCyclePop.solution[t].mNrmMin for t in range(LifeCyclePop.T_cycle)])
plot_funcs(LifeCyclePop.cFunc[: LifeCyclePop.T_retire], mMin, 5)
Consumption as a function of market resources while working:
[8]:
# Define the saving rate function
def savingRateFunc(SomeType, m):
"""Parameters
----------
SomeType:
Agent type that has been solved and simulated.
Returns
-------
SavingRate: float
"""
inc = (SomeType.Rfree[0] - 1.0) * (m - 1.0) + 1.0
cons = SomeType.solution[0].cFunc(m)
Saving = inc - cons
SavingRate = Saving / inc
return SavingRate
[9]:
# Create a Giant matrix gathering useful data:
# 't_now', 'aNrmNow_hist', 'cNrmNow_hist', employment-status in date t, in date t-1, aLvlGro_hist, Saving rate
w, h = 1, LifeCyclePop.T_cycle
giant_list = [[0 for x in range(w)] for y in range(h)]
SavingRate_list = []
import warnings
warnings.filterwarnings("ignore") # Suppress some disturbing but harmless warnings
for t in range(1, LifeCyclePop.T_cycle + 1):
# aLvlGro_hist[0] = 0 # set the first growth rate to 0, since there is no data for period 0
aLvlGroNow = np.log(
LifeCyclePop.history["aNrm"][t] / LifeCyclePop.history["aNrm"][t - 1],
) # (10000,)
# Call the saving rate function with test value for
SavingRate = savingRateFunc(LifeCyclePop, LifeCyclePop.history["mNrm"][t])
SavingRate_list.append(SavingRate)
# Create elements of matrix list
matrix_list = [0 for number in range(7)]
matrix_list[0] = t
matrix_list[1] = LifeCyclePop.history["aNrm"][t]
matrix_list[2] = LifeCyclePop.history["cNrm"][t]
matrix_list[3] = LifeCyclePop.history["TranShk"][t]
matrix_list[4] = LifeCyclePop.history["TranShk"][t - 1]
matrix_list[5] = aLvlGroNow
matrix_list[6] = SavingRate
giant_list[t - 1] = matrix_list
# Print command disabled to prevent giant print!
# print giant_list
[10]:
# Construct the level of assets A from a*p where a is the ratio to permanent income p
LifeCyclePop.history["aLvl"] = (
LifeCyclePop.history["aNrm"] * LifeCyclePop.history["pLvl"]
)
aGro41 = LifeCyclePop.history["aLvl"][41] / LifeCyclePop.history["aLvl"][40]
aGro41NoU = aGro41[aGro41[:] > 0.2] # Throw out extreme outliers
[11]:
# Plot the distribution of growth rates of wealth between age 65 and 66 (=25 + 41)
from matplotlib import pyplot as plt
n, bins, patches = plt.hist(aGro41NoU, 50, density=True)
[ ]: